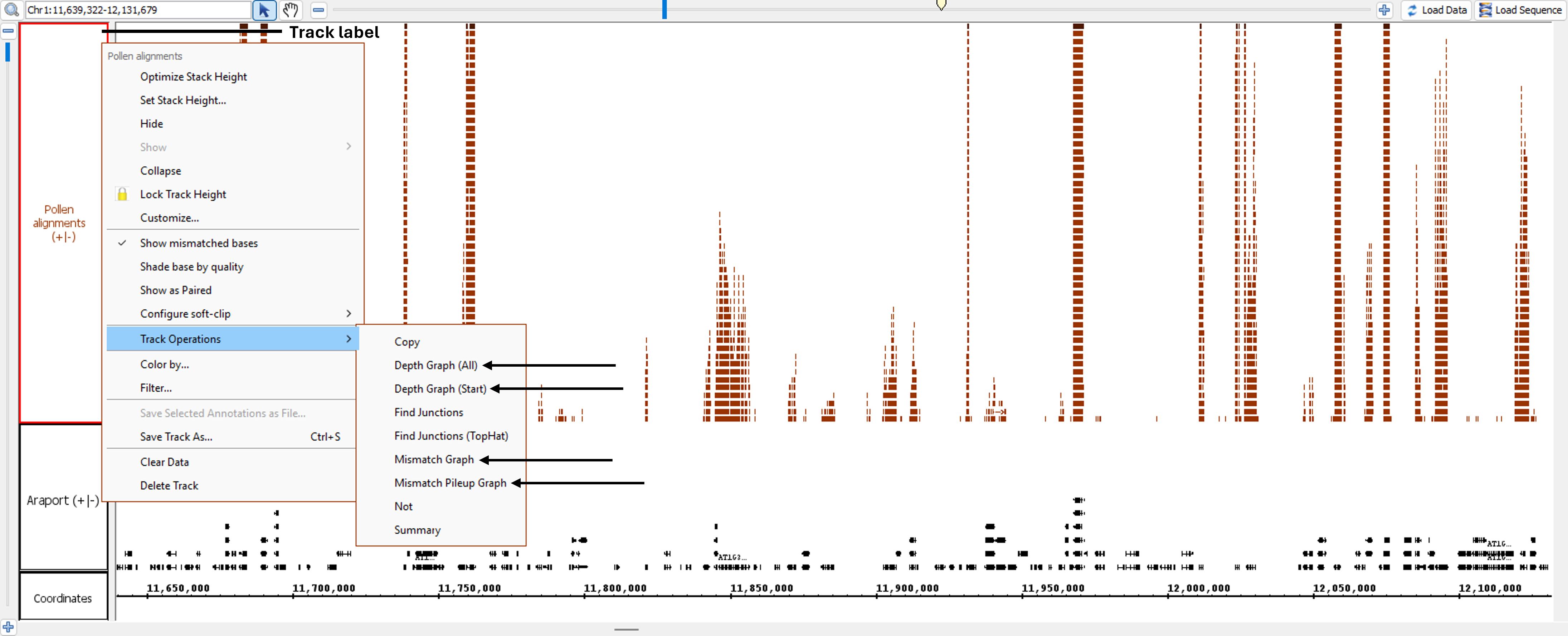
Graphs can be created by right-clicking on a track's label and highlighting Track Operations. A list of graphs and other track operations compatible with the track will then be displayed. The track operations that create graphs are:
After these graphs are created, click Load Data to load graphs for regions that have not yet been loaded. Graph tracks may be saved as .wig formatted files.
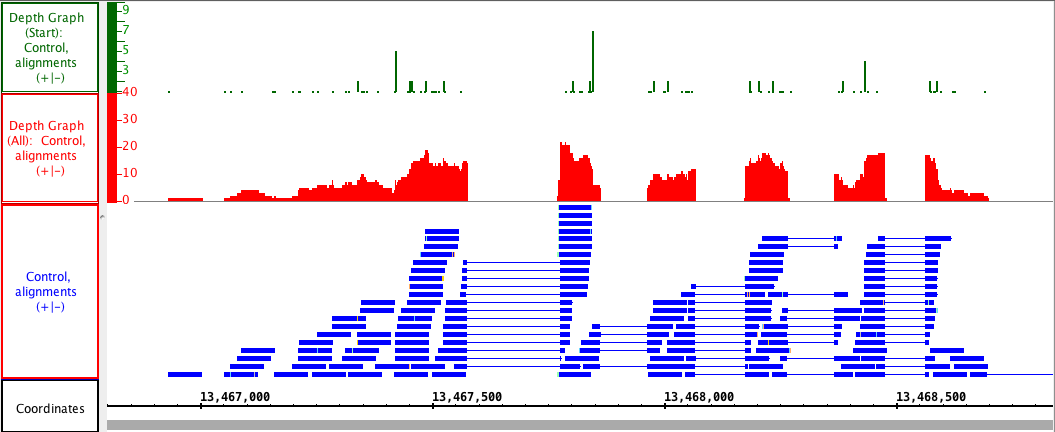
The Depth Graph feature works for all annotations but is most useful in combination with a Mismatch Graph. This allows you to see how many reads are present at each nucleotide position (Depth Graph) and where mismatches occur as compared to the genomic sequence file (Mismatch Graph).
Depth Graph (All)
Depth Graph (All) allows you to generate an overview of the relative density of annotation coverage across an entire chromosome (this is also known as a coverage graph). This feature dynamically graphs the number of annotations in a track that are present at each nucleotide across the genomic sequence. When you are completely zoomed in, and each pixel represents a single nucleotide base, the graph shows actual values for the number of reads aligned at that genomic location. Using the Select tool to hover over a particular point in the graph will open a tooltip with the actual number of reads at that point.
The first picture below shows how a fully expanded BAM file can make seeing gene annotation details difficult. The second picture shows how a depth graph summarizes the coverage of a BAM track without obscuring gene annotations (in this example, the BAM track has been hidden).
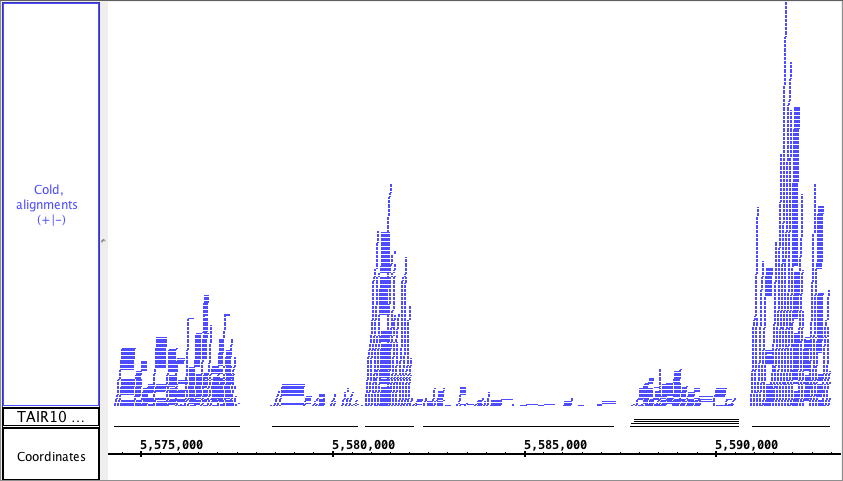
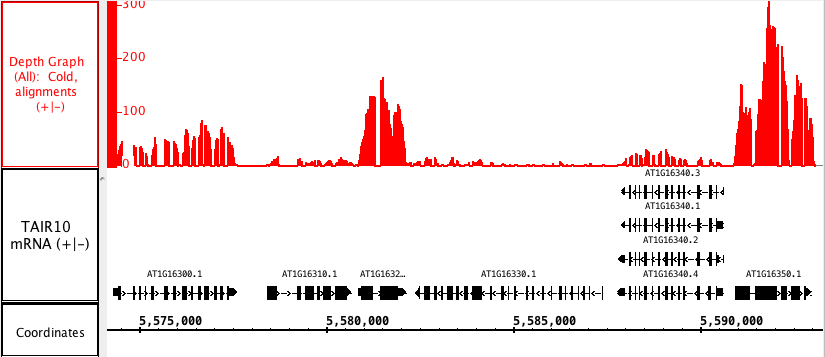
Depth Graph (Start)
Depth Graph (Start) only graphs the first nucleotide of each read. This is most useful when assessing coverage bias in RNA-Seq or other high-throughput sequencing experiments. Often some regions are better represented than others because of PCR amplification bias or other artifacts.
Mismatch Graph
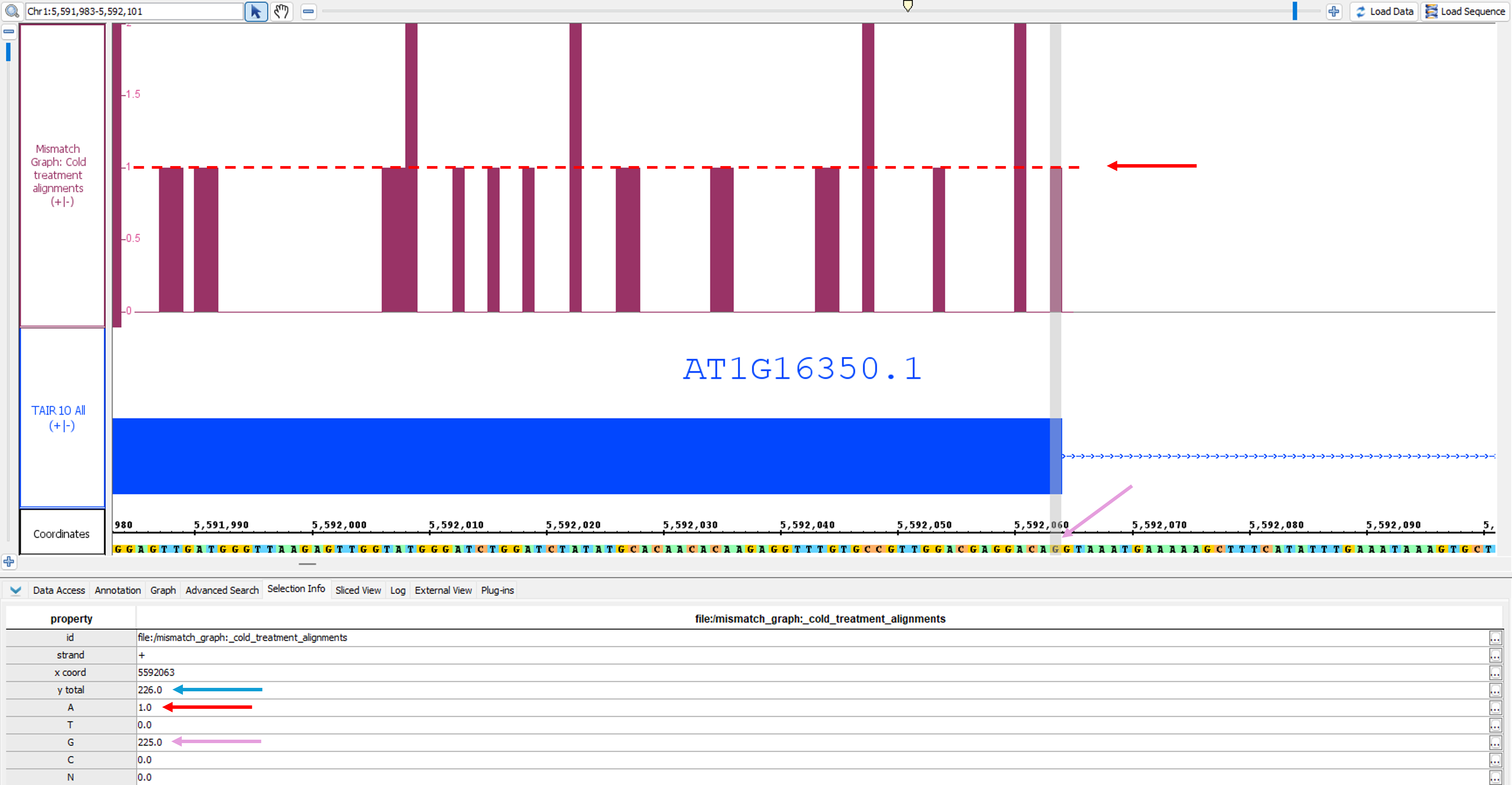
Mismatch Graph shows only the number of mismatched nucleotides across all reads at a specific genomic location, which can be very helpful in the detection of allelic variation, SNP identification, and error checking. The Mismatch Graph is specific to short read alignment files, such as BAM. Creating a Mismatch Graph requires that the genomic sequence be loaded; if it is not loaded, IGB will load the sequence for you.
If you click on any individual bar of the graph and then open the Selection Info tab at the bottom of IGB, you will get a table showing the total number of reads as well as the number of reads broken down by nucleotide at that position. In the picture below, you can see that the total number of reads at the specified position is 226 (blue arrow). Of those reads, 225 have a 'G' at that position, which you can see is the matching nucleotide in the coordinates track (purple arrows). One of those reads contains an 'A' instead; since A is a mismatch, the graph shows a bar with height of 1 (red arrows).
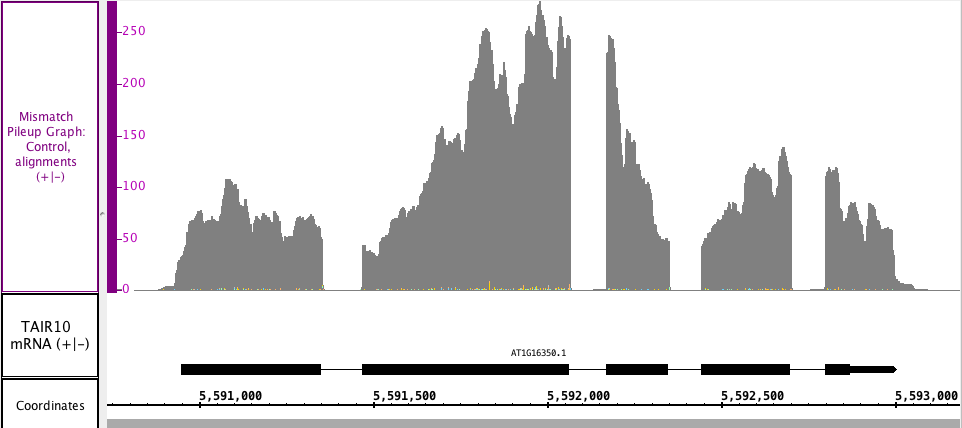
Mismatch Pileup Graph
Mismatch Pileup Graph creates a Depth Graph with a Mismatch Graph overlayed on top. The Mismatch Pileup Graph, like the Mismatch Graph, is also specific to short read alignment files, such as BAM. Creating a Mismatch Pileup Graph requires that the genomic sequence be loaded; if it is not loaded, IGB will load the sequence for you.
In the image below, you can see the Depth Graph portion of the Mismatch Pileup Graph in gray, but you can also see the mismatched, color-coded nucleotides (very small numbers in this section) from the Mismatch Graph portion along the bottom of the Mismatch Pileup Graph track.